Workflows can encourage bad system design
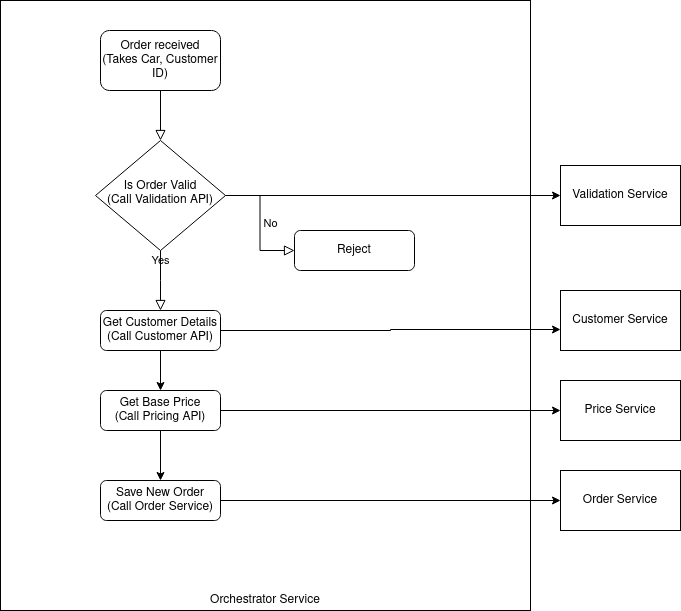
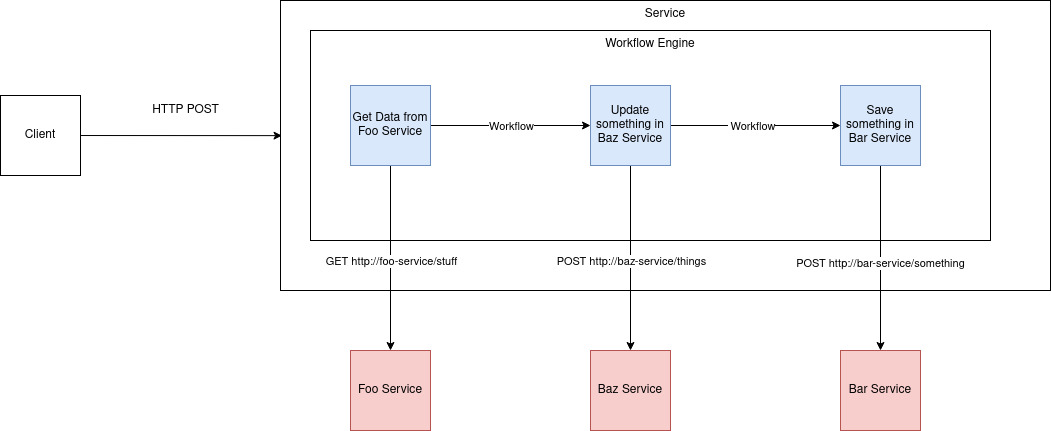
In this article I'll discuss my thoughts on a potential design flaw relating to systems (primarily microservices) which use a workflow engine. This issue was discussed in Sam Newman's excellent "Building Microservices" book. I've lived through this and felt compelled to explain my take on it! TLDR: Using a workflow engine runs the risk that other services called by the workflow are pushed to be data only with CRUD APIs and no behaviour. Centralised workflow engines that perform all behaviour should be avoided. Domain driven design should be considered first for your services. Only then consider small embedded workflow engines as a way of writing the internal code. Why Use a Workflow engine? Workflow engines are a fantastic design choice when the process you are modelling is complex and involves many sequential or parallel tasks. They can show: non technical users the actual workflow representing the process that can be easy to follow and never drifts from r